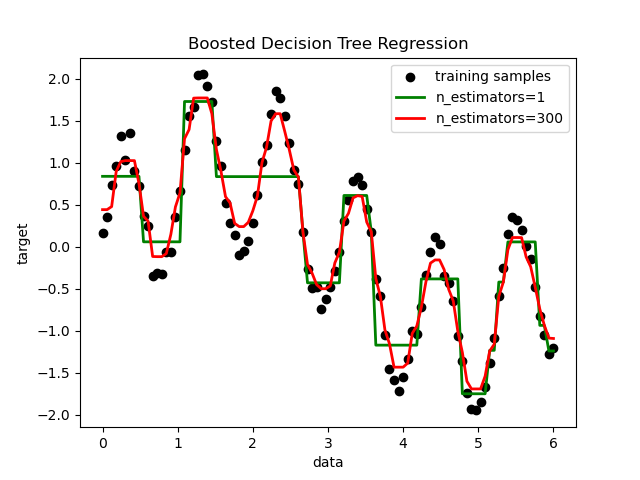
AdaBoost算法简析
概述
AdaBoost(Adaptive Boosting)是一种集成学习(Ensemble Learning)算法,旨在提高分类算法的性能。它通过将多个弱分类器(通常是简单的、性能略优于随机猜测的分类器)组合在一起,形成一个强分类器,从而实现更准确的分类。
以下是AdaBoost算法的概述:
数据准备: 首先,需要准备带有标签的训练数据集,其中每个样本都有一个已知的类别标签。
初始化权重: 对每个样本赋予一个初始权重,这些权重表示样本在训练过程中的重要性。通常情况下,初始权重相等。
迭代训练: AdaBoost通过一系列迭代来构建强分类器。在每次迭代中,它执行以下步骤:
a. 选择弱分类器: 从一组可能的弱分类器中选择一个,该选择是基于当前样本权重和分类器的性能来做出的。
b. 训练弱分类器: 使用当前样本权重对选择的弱分类器进行训练,使其在当前数据分布下尽可能准确地分类。
c. 计算错误率: 计算弱分类器在当前数据分布下的错误率,以便在下一步中进行权重调整。
d. 更新样本权重: 根据弱分类器的错误率调整样本权重,增加被错误分类的样本的权重,降低被正确分类的样本的权重。
组合弱分类器: 对于每个迭代步骤,都会为弱分类器分配一个权重,该权重基于其性能。然后,将所有弱分类器的结果按照权重加权组合起来,形成一个强分类器。
分类预测: 使用构建的强分类器来进行新样本的分类预测。强分类器将根据每个弱分类器的权重对样本进行分类,最终输出最可能的类别标签。
AdaBoost的关键思想在于每一次迭代都会调整样本的权重,将注意力集中在被错误分类的样本上,从而逐步改善分类性能。最终,通过组合多个弱分类器,AdaBoost能够产生一个在分类任务中表现良好的强分类器。
需要注意的是,AdaBoost对异常值比较敏感,因此在使用时需要谨慎处理数据异常情况。另外,AdaBoost在一些特定情况下可能会过拟合,因此可能需要进行适当的调参或者尝试其他集成学习方法。
AdaBoost与RandomForest
AdaBoost(Adaptive Boosting)和Random Forest都是集成学习算法,用于提高分类算法的性能。它们有一些共同之处,但也存在一些显著的区别。下面是它们之间的主要区别与联系:
区别:
基本分类器的选择:
- AdaBoost:AdaBoost的基本分类器是弱分类器,通常是一个简单的分类器,如决策树的深度很小。
- Random Forest:Random Forest的基本分类器是决策树,通常是深度较大的决策树。
样本权重:
- AdaBoost:AdaBoost在每次迭代中调整样本的权重,将注意力集中在被错误分类的样本上。
- Random Forest:Random Forest不调整样本权重,每棵决策树都基于原始数据进行训练。
训练方式:
- AdaBoost:AdaBoost是通过顺序迭代的方式构建弱分类器,并逐步提高其性能。
- Random Forest:Random Forest是通过并行训练多棵决策树,每棵树都在随机抽取的子样本上进行训练,然后对它们的预测结果进行投票或平均。
权重分配:
- AdaBoost:AdaBoost在构建最终分类器时,对每个弱分类器分配一个权重,用于组合它们的预测结果。
- Random Forest:Random Forest对所有决策树的预测结果进行投票(分类问题)或平均(回归问题),最终确定最终结果。
联系:
集成思想: AdaBoost和Random Forest都采用了集成学习的思想,通过组合多个基本分类器来提高整体性能。
减少过拟合: 两种算法都能有效减少过拟合的风险。AdaBoost通过调整样本权重来关注难以分类的样本,而Random Forest通过随机子样本和特征选择来增加模型的多样性,从而减少过拟合。
应用领域: 两种算法在各种应用领域都有广泛的应用,包括分类和回归问题。
模型解释: 通常情况下,Random Forest的模型比较容易解释,因为它由多个决策树组成。相比之下,由于AdaBoost使用加权投票组合多个弱分类器,解释起来可能稍微复杂一些。
在选择使用AdaBoost还是Random Forest时,你需要考虑数据特点、问题复杂度以及模型性能等因素。需要注意的是,这两种算法并不是适用于所有问题的通用解决方案,有时候其他的集成学习方法或单一模型可能更加适合。
涉及到的数学公式
初始化样本权重:
$$w_i^{(1)} = \frac{1}{N} \quad \text{for} \quad i = 1, 2, \ldots, N$$弱分类器的权重计算:
$$\epsilon_t = \sum_{i=1}^{N} w_i^{(t)} \cdot \mathbb{1}\left(h_t(x_i) \neq y_i\right)$$$$\alpha_t = \frac{1}{2} \ln\left(\frac{1 - \epsilon_t}{\epsilon_t}\right)$$
样本权重更新:
$$w_i^{(t+1)} = \frac{w_i^{(t)} \cdot \exp(-\alpha_t \cdot y_i \cdot h_t(x_i))}{Z_t} \quad \text{for} \quad i = 1, 2, \ldots, N$$其中,
$$Z_t = \sum_{i=1}^{N} w_i^{(t)} \cdot \exp(-\alpha_t \cdot y_i \cdot h_t(x_i))$$最终分类器的组合:
$$H(x) = \text{sign}\left(\sum_{t=1}^{T} \alpha_t \cdot h_t(x)\right)$$
这些公式涵盖了AdaBoost算法的核心数学原理。在这里,$N$ 表示样本数量,$x_i$ 是第 $i$ 个样本的特征,$y_i$ 是第 $i$ 个样本的标签,$h_t(x_i)$ 是第 $t$ 个弱分类器对样本 $x_i$ 的预测结果,$\alpha_t$ 是第 $t$ 个弱分类器的权重,$w_i^{(t)}$ 是第 $t$ 轮迭代中样本 $x_i$ 的权重,$T$ 是迭代轮数。
需要注意的是,这里的公式只是一个概览,实际的推导和计算过程可能会更加详细和复杂。如果你希望更深入地了解AdaBoost算法的数学原理,建议参考相关的教材、论文或在线资源。
案例:马疝病的预测
数据集

实现
1 | import numpy as np |
来源于 ApacheCN
DT与AdaBoost
1 | import matplotlib.pyplot as plt |